1. 数据库主从概念、优点、用途
主从数据库是什么意思呢,主是主库的意思,从是从库的意思。数据库主库对外提供读写的操作,从库对外提供读的操作。
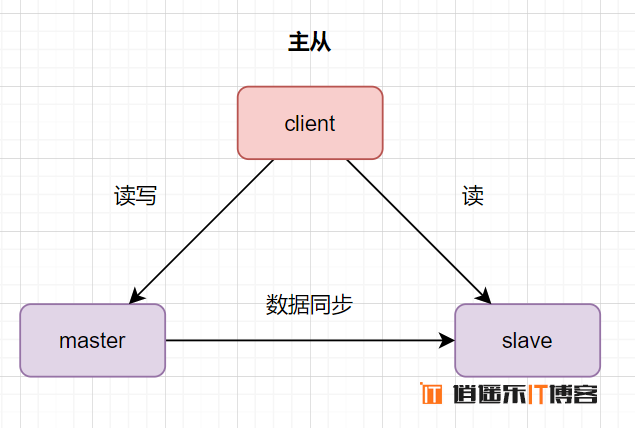
数据库为什么需要主从架构呢?
- 高可用,实时灾备,用于故障切换。比如主库挂了,可以切从库。
- 读写分离,提供查询服务,减少主库压力,提升性能
- 备份数据,避免影响业务。
2. 数据库主从复制原理
主从复制原理,简言之,分三步曲进行:
- 主数据库有个
bin log二进制文件,记录了所有增删改SQL语句。(binlog线程) - 从数据库把主数据库的
bin log文件的SQL语句复制到自己的中继日志relay log(io线程) - 从数据库的
relay log重做日志文件,再执行一次这些sql语句。(sql执行线程)
详细的主从复制过程如图:
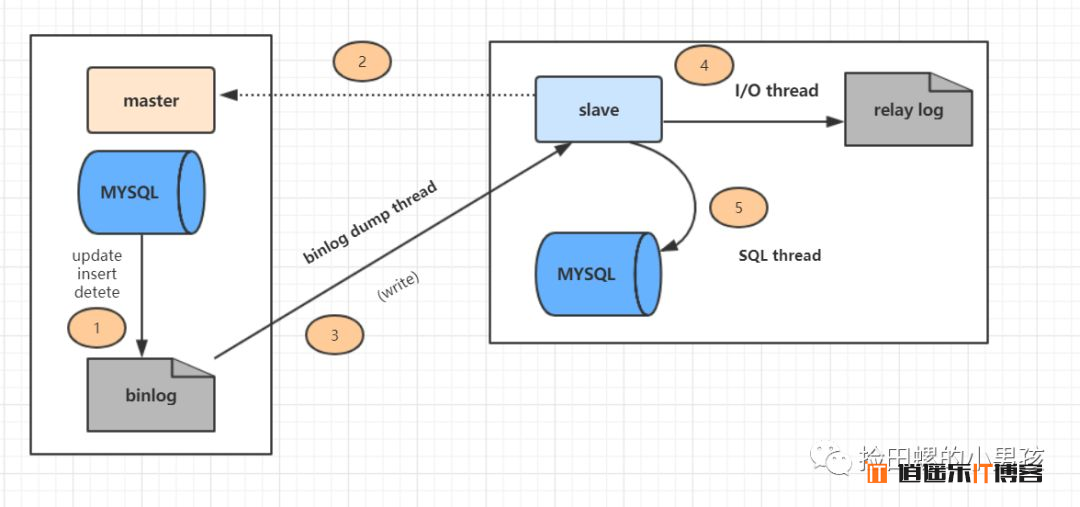
上图主从复制过程分了五个步骤进行:
- 主库的更新SQL(update、insert、delete)被写到binlog
- 从库发起连接,连接到主库。
- 此时主库创建一个
binlog dump thread,把bin log的内容发送到从库。 - 从库启动之后,创建一个
I/O线程,读取主库传过来的bin log内容并写到relay log - 从库还会创建一个SQL线程,从
relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
3.主主、主从、主备的区别
数据库主主:两台都是主数据库,同时对外提供读写操作。客户端访问任意一台。数据存在双向同步。
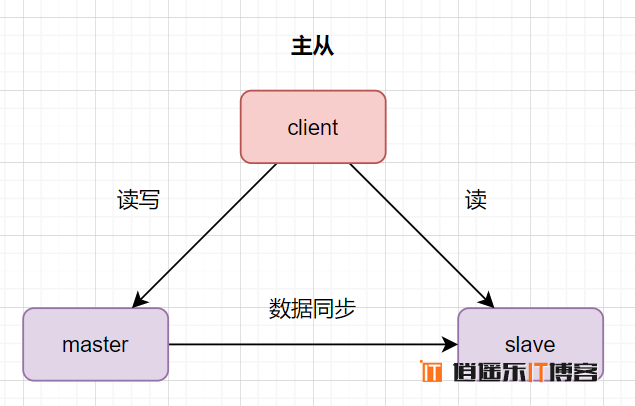
数据库主从:一台是主数据库,同时对外提供读写操作。一台是从数据库,对外提供读的操作。数据从主库同步到从库。
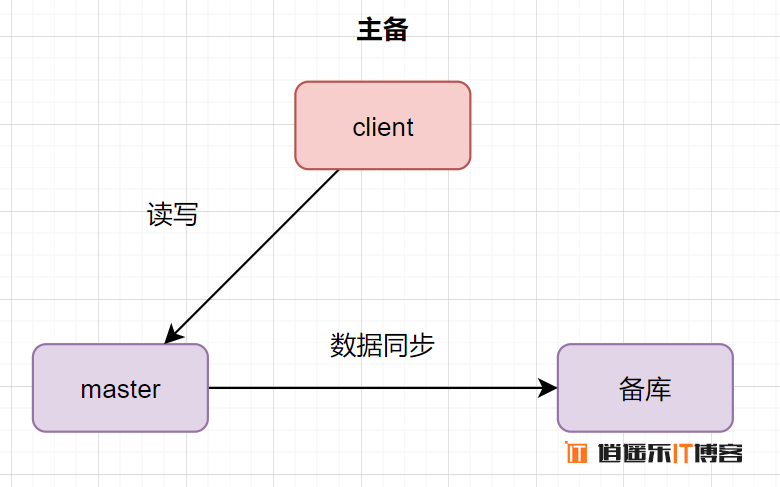
从库和备库,就是slave库功能不同因此叫法不一样而已。一般slave库都会对外提供读的功能的,因此,大家日常听得最多的就是主从。
4.MySQL是怎样保证主从一致的
我们学习数据库的主从复制原理后,了解到从库拿到并执行主库的binlog日志,就可以保持数据与主库一致了。这是为什么呢?哪些情况会导致不一致呢?
4.1长链接
主库和从库在同步数据的过程中断怎么办呢,数据不就会丢失了嘛。因此主库与从库之间维持了一个长链接,主库内部有一个线程,专门服务于从库这个长链接。
4.2binlog格式
binlog 日志有三种格式,分别是 statement,row 和 mixed。
如果是 statement 格式,binlog 记录的是 SQL的原文,如果主库和从库选的索引不一致,可能会导致主库不一致。我们来分析一下。假设主库执行删除这个SQL(其中,a 和 create_time 都会有索引)如下:
delete from t where a > '666' and create_time < '2022-03-02' limit 1;
我们知道,数据库选择了 a 索引和选择 create_time 索引,最后 limit 1 出来的数据一般是不一样的。所以就会存在这种情况:在 binlog = statement 格式时,主库在执行这条SQL时,使用的是索引a,而从库在执行这条SQL时,使用了索引 create_time。最后主从数据不一致了。
如何解决这个问题呢?
可以把binlog格式修改为 row。row 格式的 binlog 日志,记录的不是 SQL原文,而是两个 event: Table_map 和 Delete_rows。Table_map event 说明要操作的表,Delete_rows event 用于定义要删除的行为,记录删除的具体行数。row 格式的binlog记录的就是要删除的主键ID信息,因此不会出现主从不一致的问题。
但是如果SQL删除10万行数据,使用row格式就会很占空间的,10万条数据都在 binlog 里面,写 binlog 的时候也很耗IO。但是 statement 格式的binlog可能会导致数据不一致,因此设计MySQL的大叔想了一个折中的方案,mixed 格式的 binlog。所谓的 mixed格式其实就是 row 和 statement 格式混合使用,当 MySQL 判断可能数据不一致时,就用 row 格式,否则使用 statement 格式。
5.数据库主从延迟的原因与解决方案
主从延迟是怎样定义的呢?与主从数据同步相关的时间点有三个
- 主库执行完一个事务,写入binlog,我们把这个时刻记为
T1; - 主库同步数据给从库,从库接受完这个binlog的时刻,记录为
T2; - 从库执行完这个事务,这个时刻记录为
T3。
所谓主从延迟,其实就是指同一个事务,在从库执行完的时间和在主库执行完的时间差值,即 T3-T1。
哪些情况会导致主从延迟呢?
- 如果从库所在的机器比主库的机器性能差,会导致主从延迟,这种情况比较好解决,只需选择主从库一样规格的机器就好。
- 如果从库的压力大,也会导致主从延迟。比如主库直接影响业务,大家可能使用会比较克制,因此一般查询都打到从库了,结果导致从库查询消耗大量CPU,影响同步速度,最后导致主从延迟。这种情况的话,可以搞一主多从架构,即多接几个从库分摊读的压力。另外,还可以把binlog接入到Hadoop这类系统,让它们提供查询的能力。
- 大事务也会导致主从延迟。如果一个事务执行就要10分钟,那么主库执行完后,给到从库执行,最后这个事务可能就会导致从库延迟10分钟啦。日常开发中,我们为什么特别强调,不要一次性delete太多SQL,需要分批进行,其实也是为了避免大事务。另外,大表的DDL语句,也会导致大事务,大家日常开发关注一下哈。
- 网络延迟也会导致主从延迟,这种情况你只能优化你的网络啦,比如带宽20M升级到100M类似意思等。
- 如果从数据库过多也会导致主从延迟,因此要避免复制的从节点数量过多。从库数据一般以3-5个为宜。
- 低版本的MySQL只支持单线程复制,如果主库并发高,来不及传送到从库,就会导致延迟。可以换用更高版本的Mysql,可以支持多线程复制。
6.聊聊数据的库高可用方案
6.1双机主备高可用
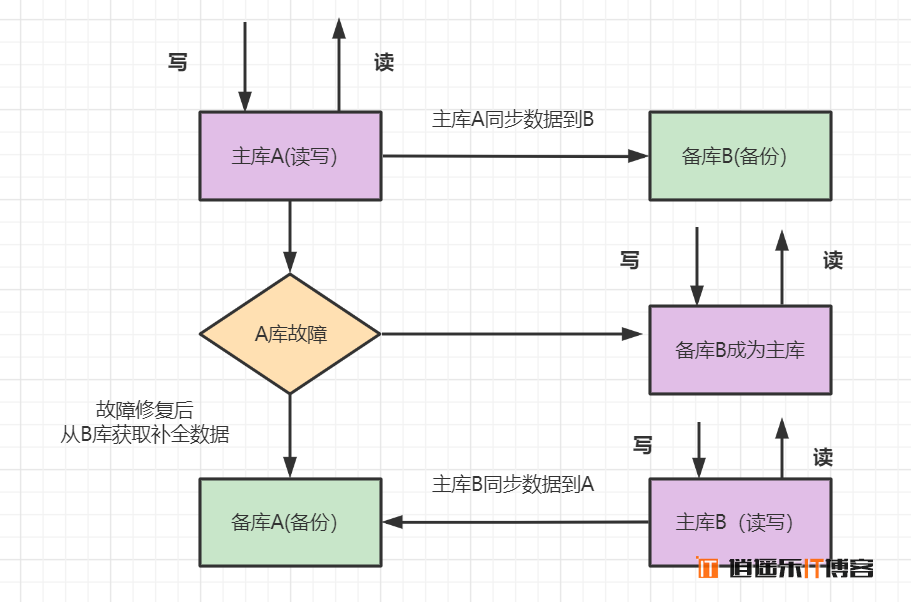
- 架构描述:两台机器A和B,A为主库,负责读写,B为备库,只备份数据。如果A库发生故障,B库成为主库负责读写。修复故障后,A成为备库,主库B同步数据到备库A
- 优点:一个机器故障了可以自动切换,操作比较简单。
- 缺点:只有一个库在工作,读写压力大,未能实现读写分离,并发也有一定限制
6.2一主一从
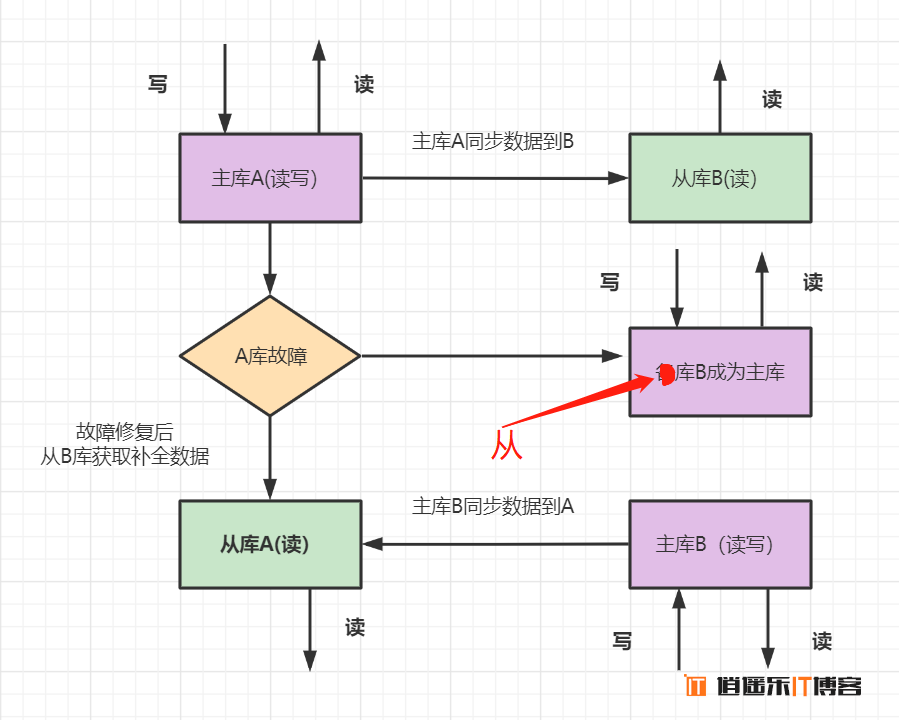
- 架构描述: 两台机器A和B,A为主库,负责读写,B为从库,负责读数据。如果A库发生故障,B库成为主库负责读写。修复故障后,A成为从库,主库B同步数据到从库A。
- 优点:从库支持读,分担了主库的压力,提升了并发度。一个机器故障了可以自动切换,操作比较简单。
- 缺点:一台从库,并发支持还是不够,并且一共两台机器,还是存在同时故障的机率,不够高可用。
6.3一主多从
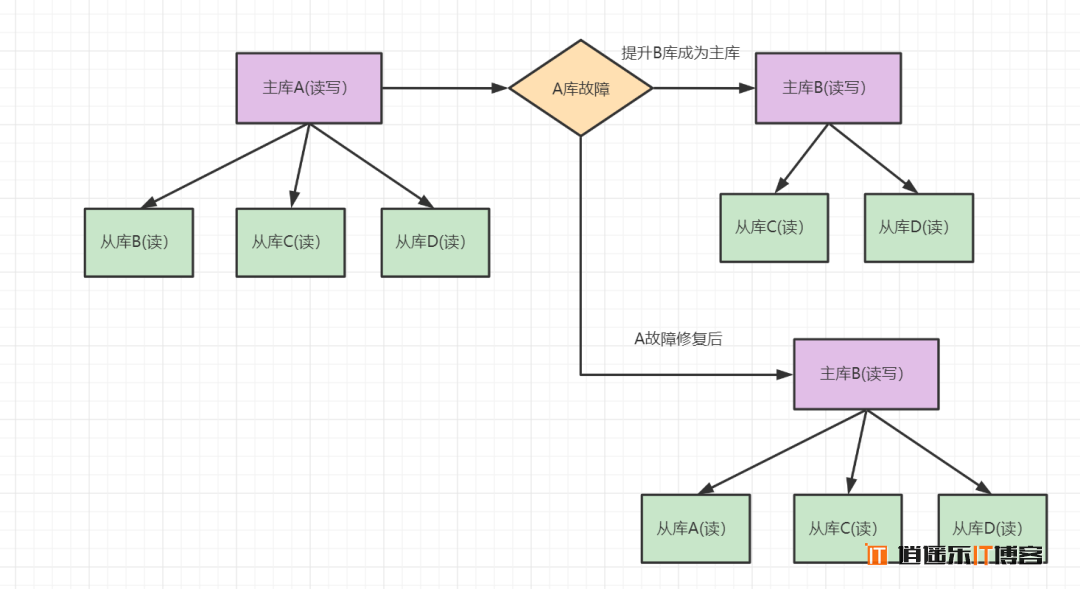
- 架构描述: 一台主库多台从库,A为主库,负责读写,B、C、D为从库,负责读数据。如果A库发生故障,B库成为主库负责读写,C、D负责读。修复故障后,A也成为从库,主库B同步数据到从库A。
- 优点:多个从库支持读,分担了主库的压力,明显提升了读的并发度。
- 缺点:只有台主机写,因此写的并发度不高
6.4MariaDB同步多主机集群
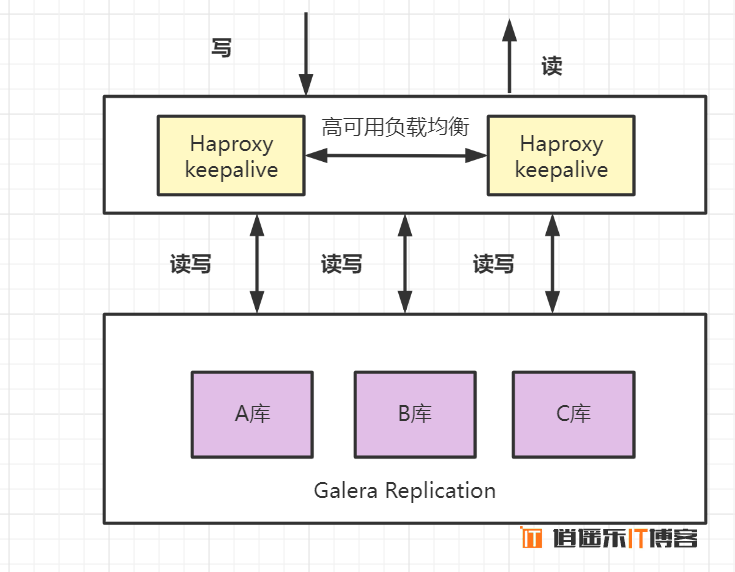
- 架构描述:有代理层实现负载均衡,多个数据库可以同时进行读写操作;各个数据库之间可以通过
Galera Replication方法进行数据同步,每个库理论上数据是完全一致的。 - 优点:读写的并发度都明显提升,可以任意节点读写,可以自动剔除故障节点,具有较高的可靠性。
- 缺点:数据量不支持特别大。要避免大事务卡死,如果集群节点一个变慢,其他节点也会跟着变慢。
6.5数据库中间件
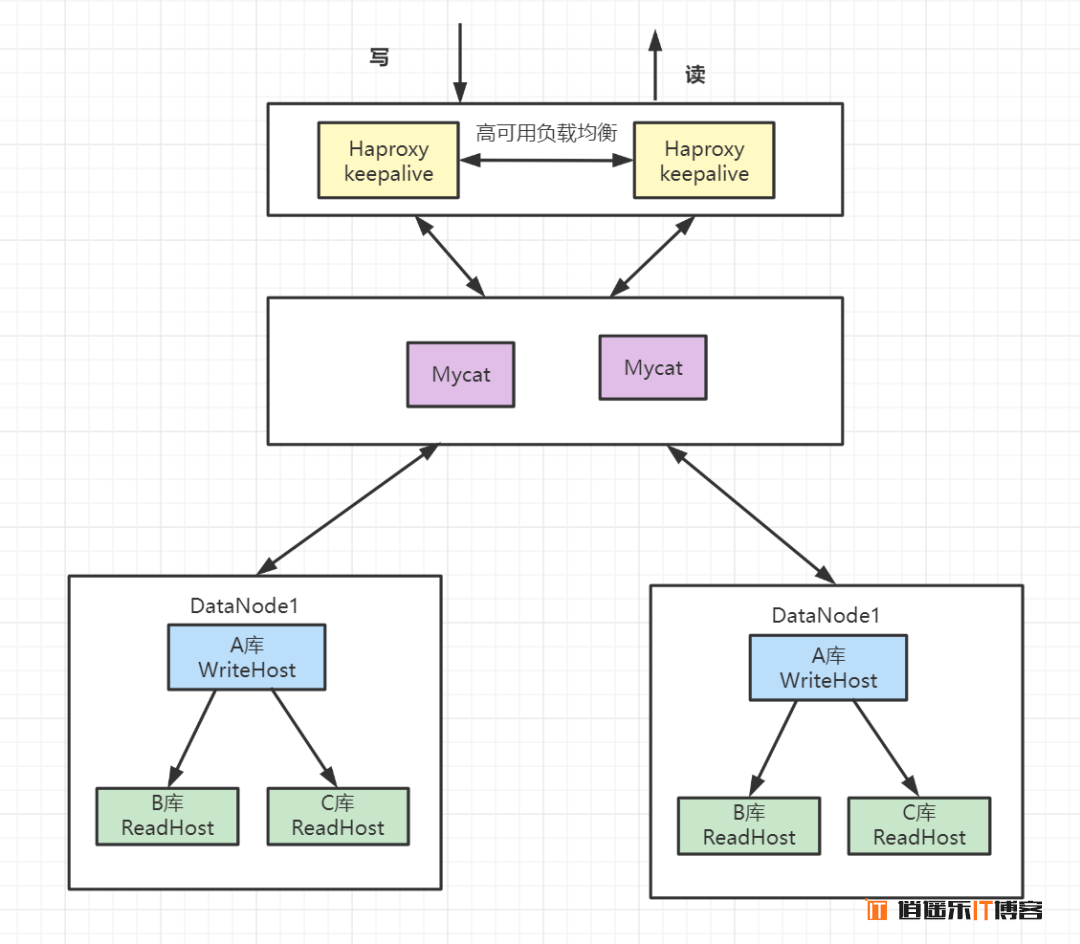
- 架构描述:mycat分片存储,每个分片配置一主多从的集群。
- 优点:解决高并发高数据量的高可用方案
- 缺点:维护成本比较大。
巨人的肩膀
微信公众号:捡田螺的小男孩



![SQL Server 2005数据库程序安装完全图文教程[附SQL Server2005完整企业版下载]](https://www.luoxiao123.cn/thumbs/0/2144.jpg)
最新评论